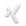Angefangen hat es mit der Lektüre von Inside Microsoft SharePoint 2013 – insgesamt eine recht gute Übersicht mit auch einigen Vertiefungen und dass mein Interesse am Ende etwas nachgelassen hat liegt vermutlich an den Themen. Es beantwortet sicher nicht alle Fragen, macht aber Lust auf mehr. Da das Thema SharePoint AddIn für mich neu war habe ich mir überlegt, mir mal die Entwicklung eines solchen AddIns an einem (Pseudo-) praktischen Beispiel anzuschauen. Natürlich wollte ich auch noch mal einige Themen wie Listen, Felder, Content Types etc. auffrischen – ja, es gibt seit WSS 3.0 Neues, aber wirklich anders ist es ja nicht: selbst die Art der SQL Datenbankablage ähnelt noch der Urform.
Diese Fokussierung ist auch einer der Gründe warum die folgenden Aussagen mit Vorsicht zu genießen sind, da sie auf gefährlichem Halbwissen basieren. Ich denke zwar, dass ich vielleicht das eine oder andere noch vertiefen werden (Join und GroupBy vor allem), aber im Grund ist mein selbst gesetztes (Zeit-)Budget für die Evaluation erschöpft. Schauen wir mal.
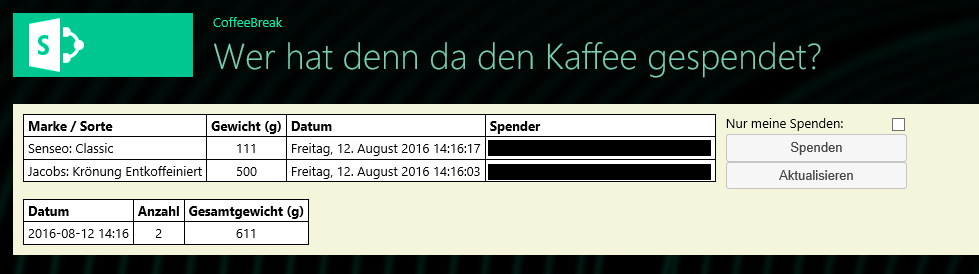
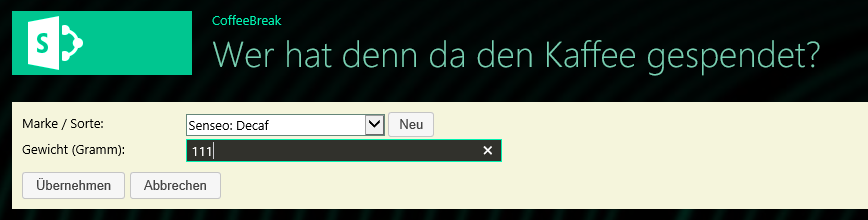
Am Anfang habe ich sehr viel die Visual Studio Assistenten zum Anlegen von Listen, Feldern und Content Types verwendet. Allerdings fand ich immer wieder Aufgaben, die dann doch nur in der XML erledigt werden konnten und hatte Änderungen in der XML vorgenommen, die der Assistent dann beim nächsten Speichern stillschweigend wieder entfernte. Die zweite Liste wurde dann sogar in ein zweites Feature eingefügt, was mich dann eine Zeit beschäftigt hat bis ich herausgefunden habe, dass deswegen ein Lookup Feld nicht funktionierte. Erstes Fazit daher: CAML lernen und direkt die XML Datei pflegen – tatsächlich nimmt der Assistent nicht wirklich viel Arbeit ab (Mindestens allerdings diese Ausnahme: alle Felder eines existierenden Content Types zur Liste hinzufügen).
Die Liste mit den Arten der Kaffeesorten sollte den Titel eigentlich als eindeutigen Schlüssel haben – im Client wird das zwar beim Anlegen geprüft, aber das passiert nur im Client Code und ist nicht Multi-User-sicher. Auch wenn das wohl inzwischen bei SharePoint Out-Of-The-Box geht habe ich darauf erst einmal verzichtet – ein Punkt den ich mir noch einmal anschauen muss: geht das auch auf dem vordefinierten Feld Title, kann man die Fehlermeldung beim Speichern auch über JSOM eindeutig identifizieren, etc.
Auch mein Lookup Feld (eine Spende referenziert genau eine Art von Kaffee) ist etwas halbherzig. Zwar unterstützt die kleine Anwendung selbst weder Löschen noch Ändern von Spenden und Arten, aber über den Direktaufruf der Listen (Lists/CoffeeTypes und Lists/Donations) geht das dann doch – ich habe glücklicherweise noch nicht herausgefunden, wie man den externen Zugriff dieser URLs gänzlich sperrt. Und das Löschen einer Kaffeesorte hinterlässt Spenden mit offenen Referenzen – laut Dokumentation soll dies aber konfigurierbar sein, daher bin ich dem nicht weiter nachgegangen. Das ist aber auch nur eine kleine Spitze eines Eisbergs: SharePoint scheint es grundsätzlich egal zu sein, ob ein Feld Required (TRUE) ist: speichern kann man irgendwie immer. Offenbar nur ein Hinweis für Formulare?
Eigentlich wollte ich das Lookup gar nicht sondern mal schauen, wie man ein Join zwischen zwei Listen in einer CAML Suche formuliert und auswertet. In der Dokumentation ist das ziemlich klar aber leider war die Zeit am Ende – vielleicht später einmal. Lookup Felder sind aber durchaus handlich, daher habe ich hier auch nicht mehr verstärkt gesucht.
Interessant war auch mein Versuch eine CAML Suche auf eine Liste Gruppieren zu lassen. Tatsächlich ist mit das nicht wirklich gelungen, herausgekommen ist nur so eine Art Sortieren: Elemente mit gleichem Wert stehen zusammen. Der Dokumentation nach geht ein echtes Gruppieren (mit Aggregation, in diesem Fall bräuchte ich ein Count() und ein Sum()) nicht mit reinen CAML Suchen sondern nur über Listen. Das kann ich mir noch nicht wirklich vorstellen, hier muss ich sicher noch einmal nachhaken. Wenn dem so ist, wäre das übel, wie man an der implementierten Lösung sieht: der Client liest alle Elemente und gruppiert selbst! Mit wachsender Anzahl von Elementen ein potentielles Performance Problem und ich würde so etwas niemals produktiv freigeben.
Die Gruppierung selbst habe ich über ein berechnetes Feld gemacht, das wiederum sehr einfach einzurichten war. Die Dokumentation der Formelsprache ist aber recht dürftig – zumindest bei Microsoft, oder ich habe mal wieder falsch gesucht. Um die App überhaupt mit einer Gruppierung nach Zeit testen zu können wird hier eine Granularität nach Minuten verwendet – realistisch wäre wohl eher nach Tag, das kann man mit der aktuellen Implementierung einfach durch Umkonfiguration des Feldes erreichen.
Nimmt man nun noch das Problem hinzu, dass SharePoint-Hosted AddIns bei der Deinstallation die Daten in den privaten Listen verlieren, dann bin ich mir nicht ganz sicher, ob das von mir überlegte Beispiel tatsächlich realistisch ist. Im Moment würde ich diese Technologie für Apps nutzen, die auf bestehenden Daten (Listen auf Site Ebene oder höher, die in das App Web hinein sichtbar sind) Zusatznutzen anbieten. Ansonsten reicht eine App evtl. alleine nicht aus. Auf der positiven Seite ist allerdings ganz klar zu sagen: mit den für andere HTML5/JavaScript verwendeten Techniken und Visual Studio lassen sich auch SharePoint Apps prima entwickeln, ohne sich auf das nackte CSS und JavaScript beschränken zu müssen.
Puh, reicht erst mal.
Aber vielleicht reicht dem einen oder anderen das wirre Zeugs hier für einen eigenen schnellen Einstieg in eine Evaluation!
Jochen