
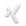


Mit dem Linux Kernel 7.1 ist der Treiber nun direkt verfügbar.
Da ich immer ab und an noch ein bisschen mit TV Karten herumspiele und meine beiden TechnoTrend Geräte inzwischen aus Altersschwäche den Geist aufgegeben haben, habe ich mit den im Titel bezeichnete Stick besorgt. Laut allen Informationen auch unter Fedora nutzbar – soweit zur Theorie.
Ich habe dann wohl ein neueres Modell bekommen, das sich mit der USB Kennung 2013:0462 meldet und für das es noch keine Unterstützung im Linux Kernel (6.18) gibt – tatsächlich auch nicht in den neueren. Hauppauge selbst verweist auf ein Open Source Paket, das es aber nur für das aktuelle Ubuntu LTS und den Kernel 6.8 gibt – dazu auch eine entsprechende Firmware.
Da es mich schon etwas Nerven gekostet hat das unter Fedora zumindest in einem Entwicklungsstand ans Laufen zu bekommen will ich hier kurz meine Erfahrungen vorstellen – auch eine längere hitzige Diskussion mit ChatGPT hat zwar ein paar mal in die richtige Richtung gezeigt mich aber auch des öfteren mal gegen die Wand laufen lassen. Basis ist der Patch für 6.8, wobei ich allerdings nur die für die 461e relevanten Teile (30.Montage.3103c.demod) extrahiert habe – mit ein paar kleinen Tweaks und einem zusätzlichen Fix für das DVB-S Tuning. Ein bisschen Code von einer Dual-Tuner Karte ist noch drin, aber das war mir egal, zumindest läuft die Karte nun erst einmal. Meinen Patch habe ich mal hier in den Blog geladen – natürlich zusammen mit dem was jetzt kommt ganz ohne Gewähr.
Ich habe das nur für mein aktuelles Fedora gemacht, wohl wissend, dass man die Module neu erstellen muss, wenn es ein Update gibt – vielleicht landet der Hauppauge Patch ja irgendwann mal im Mainstream Kernel, wer weiß. Mein uname -r meldet 6.18.3-200.fc43.x86_64 und das wird auch im folgenden Beispiel so verwendet.
Wichtig ist vor allem, dass man die richtigen Quellen verwendet – auf den ganzen Entwicklerkram, den man installieren muss, gehe ich hier nicht ein, vieles war auf meiner Entwicklermaschine eh schon drauf. Nach einigen Sackgassen fängt das so an – für die Details und meine aktuell verwendete Vorgehensweise habe ich mein eigenes Script unten angehängt, nur das aktualisiere ich in hier, der Text sollte als roter Faden verstanden werden:
Als Arbeitsverzeichnis verwende ich den Vorschlag vom rpmdev:
- rpmdev-setuptree (einmalig beim ersten Mal)
- cd ~/rpmbuild/SRPMS
Die passenden Quellen werden heruntergeladen und entpackt:
- dnf download –source kernel-6.18.3-200.fc43.x86_64
- rpm -Uvh kernel-6.18.3-200.fc43.src.rpm
Die Quellen werden passend zu meinem System konfiguriert:
- cd ../SPECS
- rpmbuild -bp kernel.spec
Der Rest findet nun in dem Verzeichnis statt in das die Quellen entpackt wurden:
- cd ../BUILD/kernel-6.18.3-build/kernel-6.18.3/linux-6.18.3-200.fc43.x86_64
Darin wird die Konfiguration des laufenden Kernels abgelegt:
- cp /boot/config-$(uname -r) .config
- make olddefconfig
fedora ist etwas pingelig was die Versionskennzeichung der Module angeht. Sollte wie im Beispiel ein Zusatz an der Version (6.18.3) vorhanden sein, so muss dieser in die Datei .config eingetragen werden. Dazu wird CONFIG_LOCALVERSION auf „-200.fc43.x86_64“ gesetzt.
Danach kann man meinen minimalisierten Patch anwenden (es gibt sechs Warnungen, da war ich wohl bezüglich Leerzeichen etwas schlampig) und bauen:
- git apply fedora43_6.17.12-300.patch
- make prepare -j$(nproc)
- make -C /lib/modules/$(uname -r)/build M=$PWD/drivers/media/usb/em28xx modules srctree=$PWD -j$(nproc)
- make -C /lib/modules/$(uname -r)/build M=$PWD/drivers/media/dvb-frontends modules srctree=$PWD -j$(nproc)
Relevant für den Zugriff auf das Gerät sind nur die folgenden drei Module:
- drivers/media/dvb-frontends/m88ds3103.ko
- drivers/media/usb/em28xx/em28xx.ko
- drivers/media/usb/em28xx/em28xx-dvb.ko
Beispiel mit VLC – Kaffeine und meine eigene Software tun es aber auch.
vlc dvb-s2://frequency=11494000:polarization=H:srate=22000000:modulation=8PSK:fec=2/3
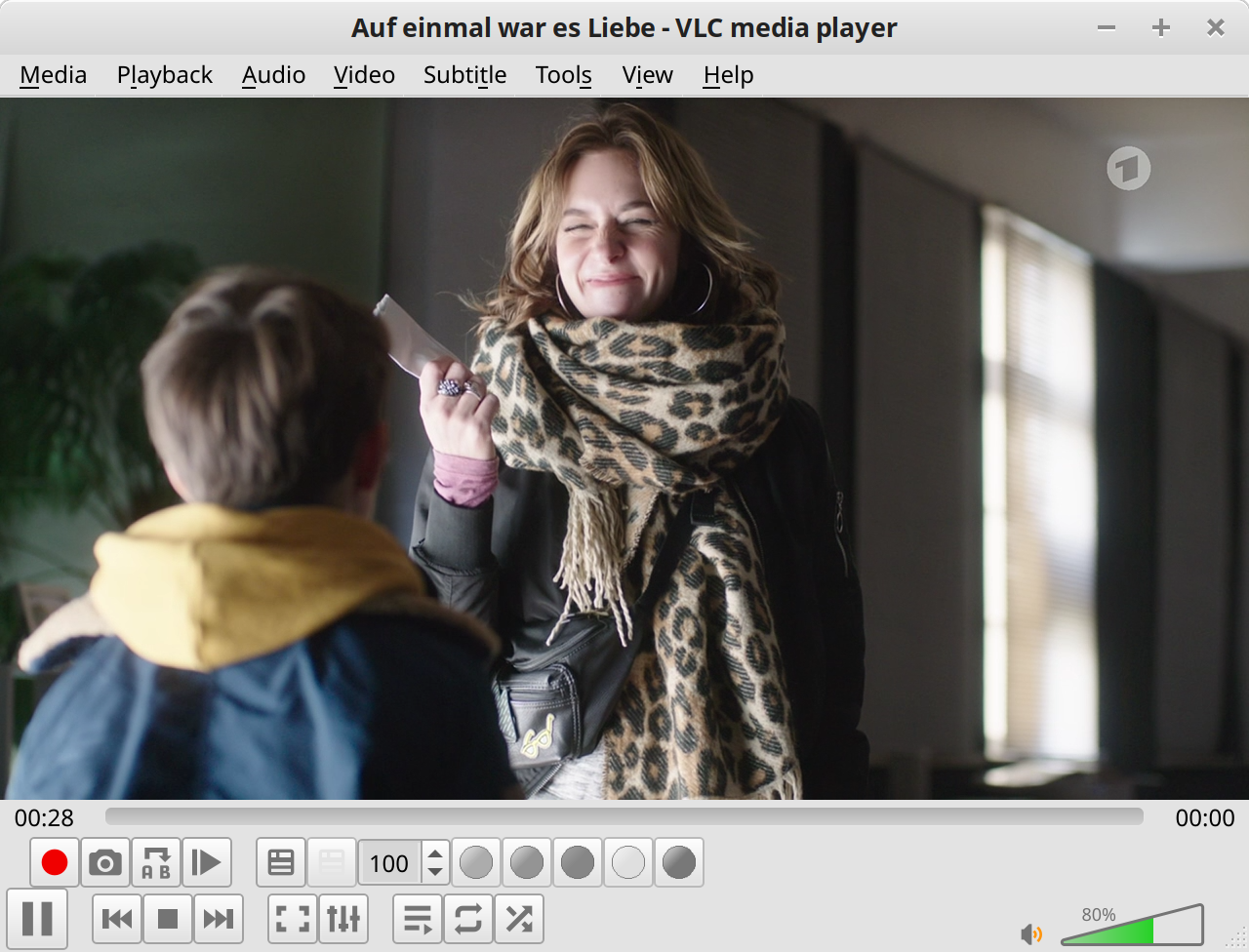
Mit dem gegenüber der ursprünglichen Version zusätzlichen Fix gehen das dann auch für DVB-S Transponder.
vlc dvb-s://frequency=12188000:polarization=H:srate=27500000:fec=3/4
Viel Glück beim Selbstversuch und im Sinne des letzten Bildes schon mal ein frohes Weihnachtsfest
Jochen
Kleiner Zusatz: tatsächlich funktioniert die DiSEqC 1.0 Ansteuerung nicht, ich vermute aber, dass ich da irgendwas übersehen habe – bezüglich des DVB-S Fixes berichtet ein Benutzer, dass er 3 DiSEqC Positionen erfolgreich angesteuert hat. Was allerdings geht ist DiSEqC Burst zum Umschalten zwischen zwei Positionen und mehr habe ich eh nicht – also für mich ist der Stick nun voll nutzbar.
Weitere Information: mit Kernel 6.18 musste ich die Anleitung noch mal überarbeiten, ich habe keinen Retest der veränderten Beschreibung für 6.17 gemacht – viel Glück für den, der es versucht. Den Patch selbst konnte ich unverändert übernehmen.
Hier mal das Script das ich (mit sudo) anwende um die Module für einen neuen Kernel zu erstellen und aktivieren:
#/bin/sh
set -ep
DIR="$( cd -- "$(dirname "$0")" >/dev/null 2>&1 ; pwd -P )"
# Download the patch file
curl http://jochen.jochen-manns.de/wp-content/uploads/2025/12/patch.zip -o /tmp/patch.zip
unzip -o -q /tmp/patch.zip -d /tmp/patch
# Download kernel source archive
KERNEL=`uname -r`
KERNELFED=`echo $KERNEL | sed s/\.x86_64//`
KERNELVER=`echo $KERNELFED | sed s/-.*//`
rpmdev-setuptree
cd ~/rpmbuild/SRPMS
dnf download --source kernel-$KERNELFED
# Unpack kernel source dir
SOURCEDIR=~/rpmbuild/BUILD/kernel-$KERNELVER-build/kernel-$KERNELVER/linux-$KERNEL
rm -rf $SOURCEDIR
rpm -Uvh kernel-$KERNELFED.src.rpm
# Prepare build folder
cd ../SPECS
rpmbuild -bp kernel.spec
# Load active configuration
cd $SOURCEDIR
cp /boot/config-$KERNEL .config
make olddefconfig
# Update configuration to full version
KERNELSUFFIX=`echo $KERNEL | sed s/.*-/-/`
sed -i 's/CONFIG_LOCALVERSION=""/CONFIG_LOCALVERSION="'$KERNELSUFFIX'"/' .config
# Apply patch and prepare build environment
git apply /tmp/patch/fedora43_6.17.12-300.patch
make prepare -j$(nproc)
# Build modules
make -C /lib/modules/$KERNEL/build M=$PWD/drivers/media/usb/em28xx modules srctree=$PWD -j$(nproc)
make -C /lib/modules/$KERNEL/build M=$PWD/drivers/media/dvb-frontends modules srctree=$PWD -j$(nproc)
# Hide kernel modules - will take precendence over our modules
KERNELDIR=/lib/modules/$KERNEL
for m in dvb-frontends/m88ds3103 usb/em28xx/em28xx usb/em28xx/em28xx-dvb; do
mv $KERNELDIR/kernel/drivers/media/$m.ko.xz $KERNELDIR/kernel/drivers/media/$m.backup
done
# Install custom modules
for m in dvb-frontends/m88ds3103 usb/em28xx/em28xx usb/em28xx/em28xx-dvb; do
cp drivers/media/$m.ko $KERNELDIR/kernel/drivers/media/$m.ko
done
depmod -a $KERNEL
# Verify result
modprobe em28xx


