
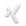


Das Äquivalent zum relationalen SQL JOIN ist bei MongoDb die $lookup Aggregation. In der einfachsten Fassung trivial in der Handhabung, aber wenn es dann doch mal wieder etwas anspruchsvoller wird muss man vielleicht wie ich doch ins Handbuch schauen. Vielleicht hilft dem einen oder anderen ein kleines Beispiel, das neben der erweiterten Form von $lookup auch noch einige andere lustige Features verwendet.
Im (vereinfachten) Beispiel geht es um eine Collection (videos) mit Filmen. Relevant für das folgende sind nur diese Eigenschaften:
- _id: die eindeutige Kennung eines Films
- published: gesetzt (true), wenn der Film zur Benutzung freigegeben ist
- tags: eine Verschlagwortung als Feld von Zeichenketten
Eine weitere Collection (playlists) fasst Filme zu Listen zusammen, die dann weitere Eigenschaft zur Vorauswahl enthalten können. Hier ist nur folgende Eigenschaft von Interesse:
- videos: ein Feld mit eindeutigen Kennungen von Filmen
Die Aufgabe war es nun, alle Listen zu einer vorgegebenen Verschlagwortung zu finden und geeignet zu sortieren. Spannend an dem beschriebenen Ansatz ist, dass eine Liste keine eigene Verschlagwortung besitzt, sondern die seiner Filme erbt – natürlich hat das wie alles seine Vor- und Nachteile. Die Verschlagwortung von nicht freigegebenen Filmen wird nicht berücksichtigt.
Auf der playlist Collection beginnt die Aggregation Pipeline daher mit einem $lookup:
- from: ‚videos‘ für ein JOIN mit den Filmen
- as: ‚tags‘ als Name des neuen Feldes
- let: { videos: ‚$videos‘ } definiert für den JOIN die Liste der Kennungen
- pipeline: { $match: { $expr: { $in: [‚$_id‘, ‚$$videos‘] }, published: true } } verwendet diese Liste für ein konventionelles JOIN (als Fremdschlüssel auf den Primärschlüssel _id), beschränkt das Ergebnis aber auch auf freigegebene Filme
Das tags Feld von Filmen wird im nächsten Schritt (auch ein $addFields) der Pipeline in ein Feld von Schlagworten umgesetzt.
- tags: { $reduce: { in: { $setUnion: [‚$$value‘, { $ifNull: [‚$$this.tags‘, []] }] }, initialValue: [], input: ‚$tags‘ } } verwendet nicht einfach $concatArrays sondern $setUnion und stellt so sicher, dass die berechnete Verschlagwortung jeder Liste jedes Schlagwort nur einmal enthält.
Im konkreten Beispiel wird ein Feld von Schlagworten (matchTags) vorgegeben und Listen werden danach bewertet, wie viele Schlagworte einer Liste tatsächlich übereinstimmen. Dazu werden weitere berechnete Felder mit einem separaten $addFields Schritt in die Pipeline aufgenommen.
- tagMatch: { $size: { $setIntersection: [‚$tags‘, matchTags] } } bildet für jede Liste die Schnittmenge mit dem vorgegebenen Feld und daraus dann die Anzahl der passenden Schlagworte – 0 bedeutet, dass kein Schlagwort der Vorgabe entspricht, bei 1 passt genau ein Schlagwort und so weiter.
- _random: { $rand: {} } kommt gleich noch und unterstützt eine mit MongoDb 4.4.2 eingeführte neue Funktionalität.
Mit einem $match Schritt kann die Pipeline erweitert werden, um die Listen auf eine Passung gemäß den vorgegebenen Schlagworten zu prüfen – Einschränkungen auf Listen an sich (sagen wir mal: nur Listen, die von einer bestimmten Person erstellt wurden) sollten natürlich ganz am Anfang der Pipeline stehen um das initiale $lookup auf die kleinste benötigte Anzahl von Listen zu beschränken.
Hier ein paar Beispiele:
- { tagMatch: 0 } lässt nur Listen zu, in denen keine der Vorgaben passt
- { tagMatch: {$gte: 2} } verlangt, dass eine Liste mindestens zwei der Schlagworte aus der Vorgaben haben muss
Im Ergebnis soll nun eine absteigende Sortierung nach der Passung (übereinstimmende Schlagworte gemäß der Vorgabe) erfolgen. Innerhalb eines Bereichs gleicher Passung sollen die Liste in zufälliger Reihenfolge erscheinen. Das macht dann ein $sort Schritt – wichtig ist natürlich die Reihenfolge der Sortierung, die Passung kommt immer zuerst:
- { tagMatch: -1, _random: 1 } wobei die Richtung der Folgesortierung nach der Zufallszahl natürlich irrelevant ist und auch absteigend erfolgen kann.
Eigentlich ist unsere Aufgabe nun vollständig erledigt, aber auf Kosten einer sauberen Schnittstelle (API) werden im Ergebnis noch mit einem letzten Schritt in der Pipeline alle berechneten Felder wieder entfernt:
- { $unset: [‚_random‘, ‚tags‘, ‚tagMatch‘] }
In der Zusammenfassung soll dieser Artikel auf folgende Aspekte einer MongoDb Aggregation neugierig machen:
- $lookup mit let und pipeline – das vollständige Äquivalent eines relationalen SQL JOIN
- $addFields mit $reduce, $setUnion und $setIntersection – Umgang mit Mengen statt Feldern
- $rand – zufällige Werte, hier praktisch für eine zufällige Sortierung (nicht Auswahl, das wäre $sample)
- $unset – für eine Block Box Funktionalität bereits in der Datenbank
Have Fun!
Jochen
[
{
$lookup: {
as: 'tags',
from: 'videos',
let: { videos: '$videos' },
pipeline: [
{
$match: {
$expr: { $in: ['$_id', '$$videos'] },
published: true,
},
},
],
},
},
{
$addFields: {
tags: {
$reduce: {
in: { $setUnion: [
'$$value',
{ $ifNull: ['$$this.tags', []] }
] },
initialValue: [],
input: '$tags',
},
},
},
},
{
$addFields: {
_random: { $rand: {} },
tagMatch: { $size: { $setIntersection: ['$tags', matchTags] } },
},
},
{ $match: { tagMatch: { $gte: 1 } } },
{ $sort: { tagMatch: -1, _random: 1 } },
{ $unset: ['_random', 'tags', 'tagMatch'] },
]